StreamVault: Mass Asset Retrieval Platform
A high-performance S3 bulk downloader designed to overcome a critical limitation in the AWS S3 ecosystem: the inability to efficiently download entire folder hierarchies containing numerous files.
AWS S3's Native Interface Limitations
AWS S3's native interface presents significant challenges when managing bulk operations.
No Native Folder Downloads
The S3 Console doesn't support downloading entire folder structures.
Limited Batch Operations
Managing thousands of files becomes unwieldy through the standard interface.
Technical Barriers
Alternative solutions require AWS CLI proficiency or custom API development.
Resource Consumption
Naive implementations risk memory exhaustion and connection timeouts.
Key Storage and Job Handling Features
StreamVault delivers a scalable, memory-efficient approach to bulk downloads through advanced queuing systems and streaming architecture.
All generated ZIP archives are stored directly in your S3 bucket at the destination path configured in your .env file.
If multiple users request the same folder, StreamVault returns the existing archive URL instead of regenerating the archive.
Job results are maintained for a configurable period (default: 1 hour) before being expired from the system.
By leveraging S3 for storage and Redis for job state management, the system maintains minimal local resource usage.
Progressive ZIP generation without requiring full local storage, enabling efficient processing of large archives.
Configurable authentication for download access with pre-signed URLs and customizable expiration times.
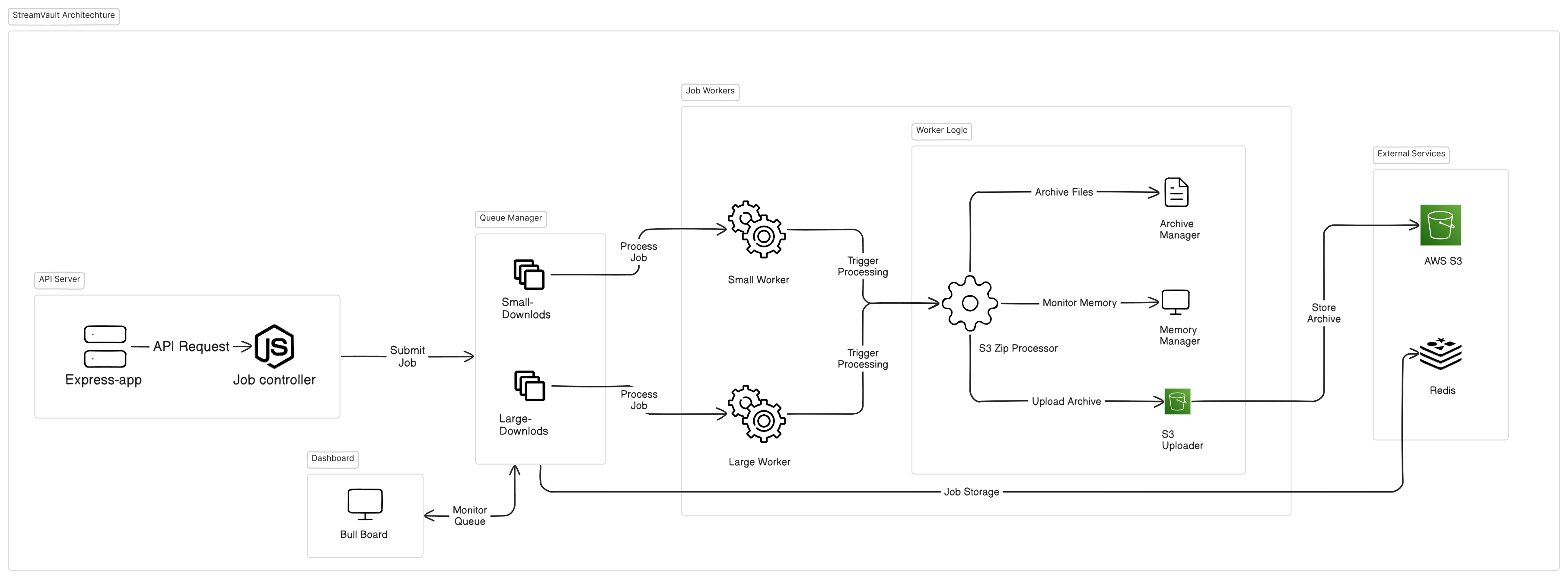
StreamVault Solution Architecture
StreamVault employs a sophisticated, microservices-based architecture to process bulk S3 downloads efficiently.
- API Server
Handles client requests, job validation, and queue management
- Redis Queue
Distributes workload and maintains job state
- Worker Nodes
Execute download and archival operations with resource management
- Monitoring Dashboard
Provides real-time visibility into system operations
- Job Processor
Manages job execution, including download and archival processes
Deploy StreamVault in Minutes
Follow these simple steps to get StreamVault up and running.
# Service Configuration NODE_ENV=development # Environment mode (development/production) PORT=3000 # API service port # Redis Configuration REDIS_HOST=redis # Redis server host REDIS_PORT=6379 # Redis server port REDIS_CONNECTION_TIMEOUT=60000 # Redis connection timeout in ms REDIS_PASSWORD=your_redis_password # Redis password (if applicable) # AWS Configuration AWS_REGION=us-east-1 # AWS region AWS_ACCESS_KEY_ID=your_key # AWS credentials AWS_SECRET_ACCESS_KEY=your_secret # AWS credentials AWS_BUCKET_NAME=your_bucket_name # S3 bucket name AWS_S3_EXPORT_DESTINATION_PATH=your_export_path # S3 export path AWS_S3_GENERATE_PRESIGNED_URL=true # Generate pre-signed URLs for downloads AWS_S3_PRESIGNED_URL_EXPIRATION=3600 # Pre-signed URL expiration time in seconds
Performance Benchmarks
StreamVault delivers consistent performance even with large workloads, maintaining low memory usage and rapid processing.
| Scenario | Files | Total Size | Processing Time* | Peak Memory | Testing Status |
|---|---|---|---|---|---|
| Small Archive | 100 | 500MB | 45s | 220MB | Tested |
| Medium Archive | 1,000 | 5GB | 8m 20s | 340MB | Tested |
| Large Archive | 25,000 | 50GB | 1h 45m | 480MB | Tested |
| Enterprise Scenario | 100,000+ | 500GB+ | ~18h** | 510MB** | Projected |
*Processing times depend on network bandwidth and S3 throttling limits
**Projected values based on small-to-large scale testing; not yet verified with actual 500GB+ workloads
All benchmarks were conducted on an AWS t2.large instance with the following specifications:
- CPU2 vCPUs
- RAM8GB
- NetworkUp to 1Gbps (burst capacity)
This demonstrates that StreamVault can handle substantial workloads even on moderately-sized infrastructure, making it suitable for teams with various resource constraints.
See StreamVault in Action
Visual overview of the StreamVault interface and monitoring capabilities.
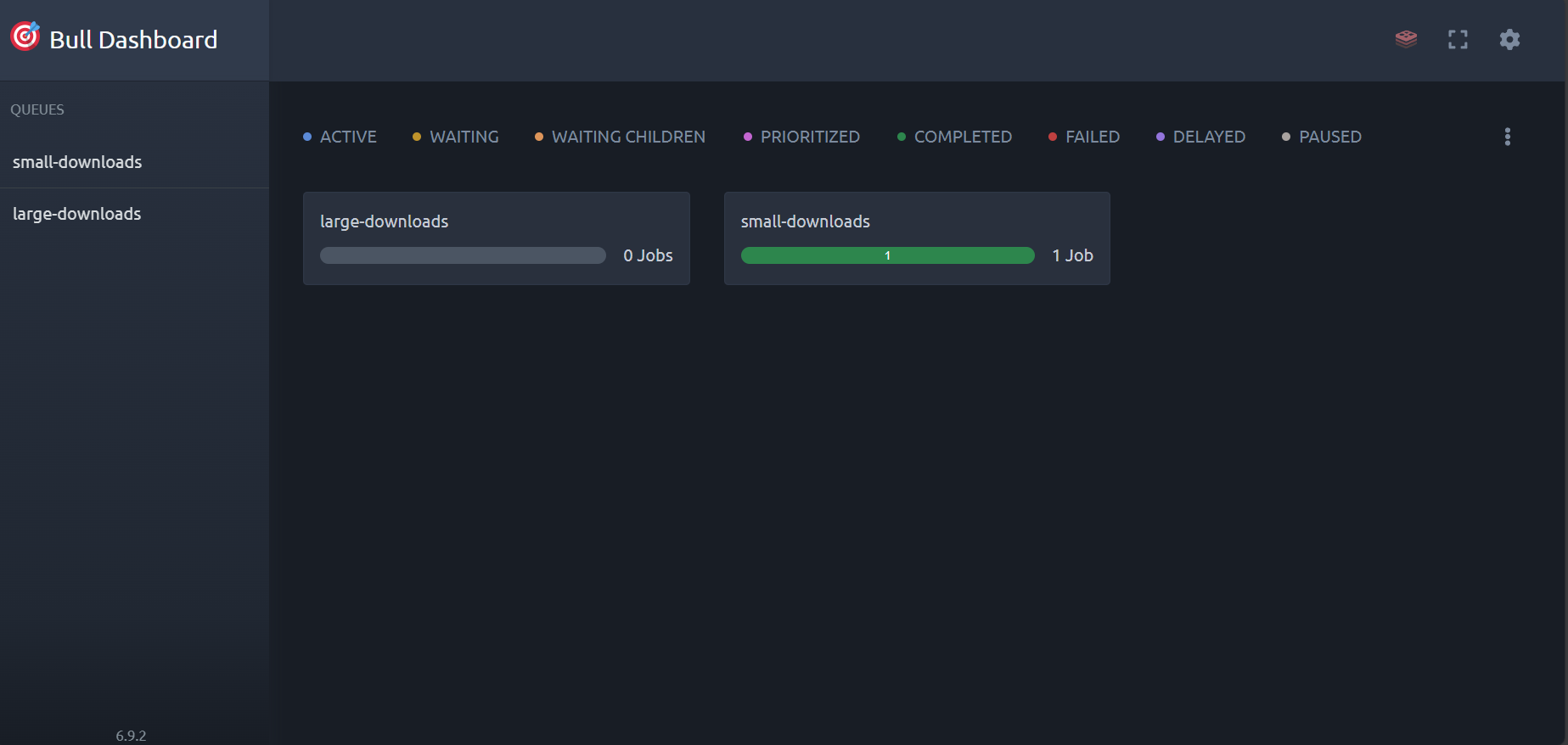
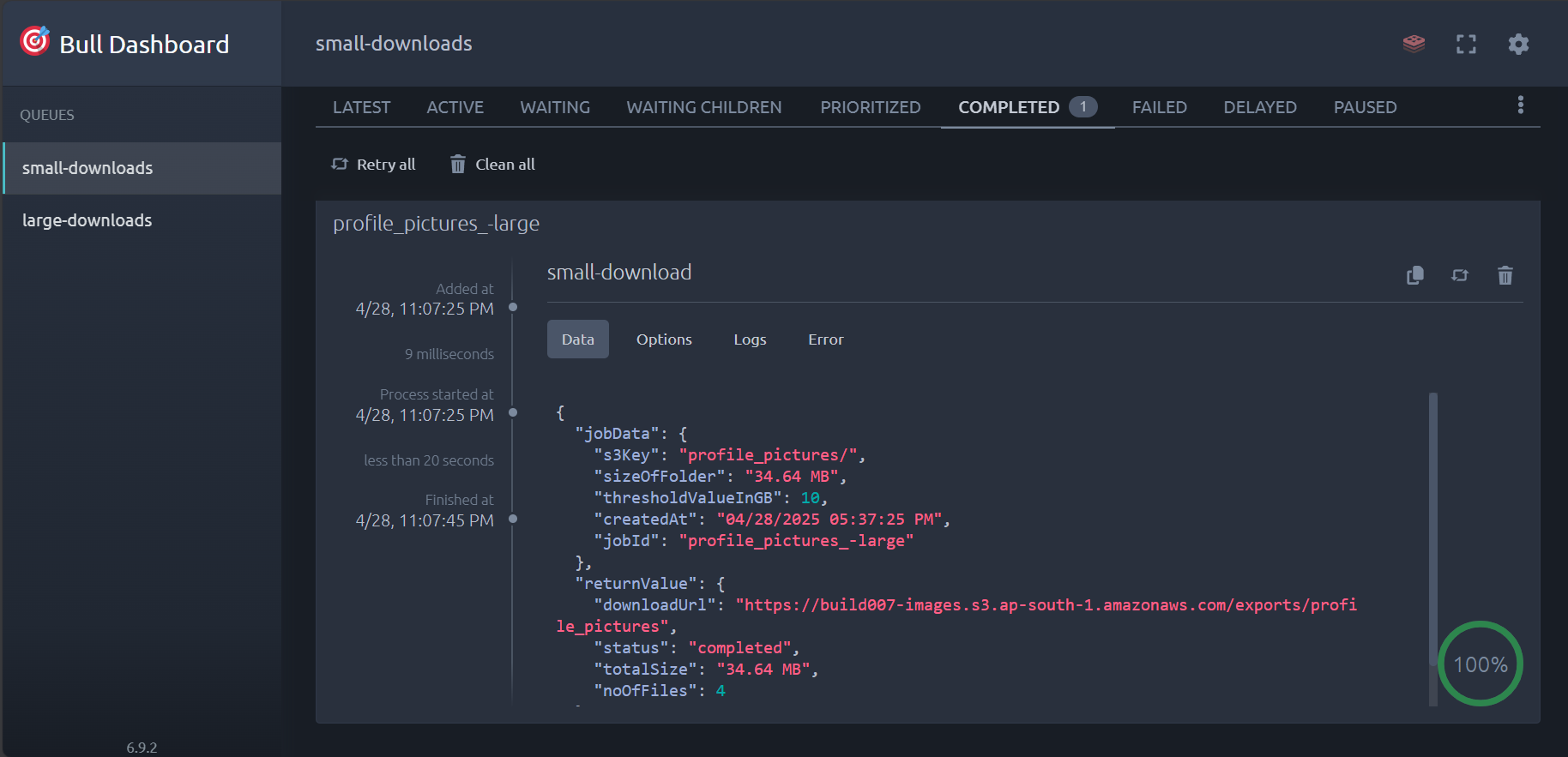
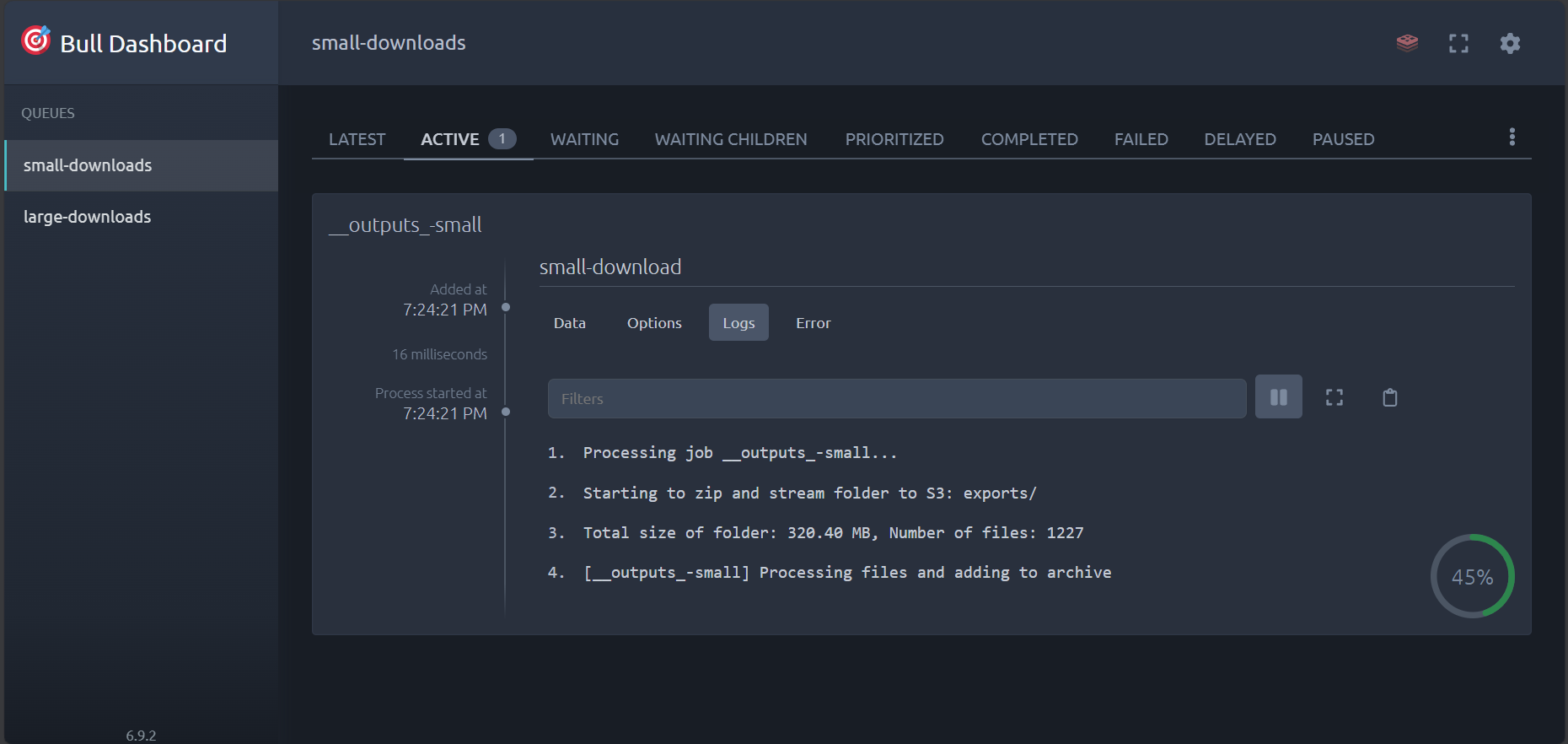
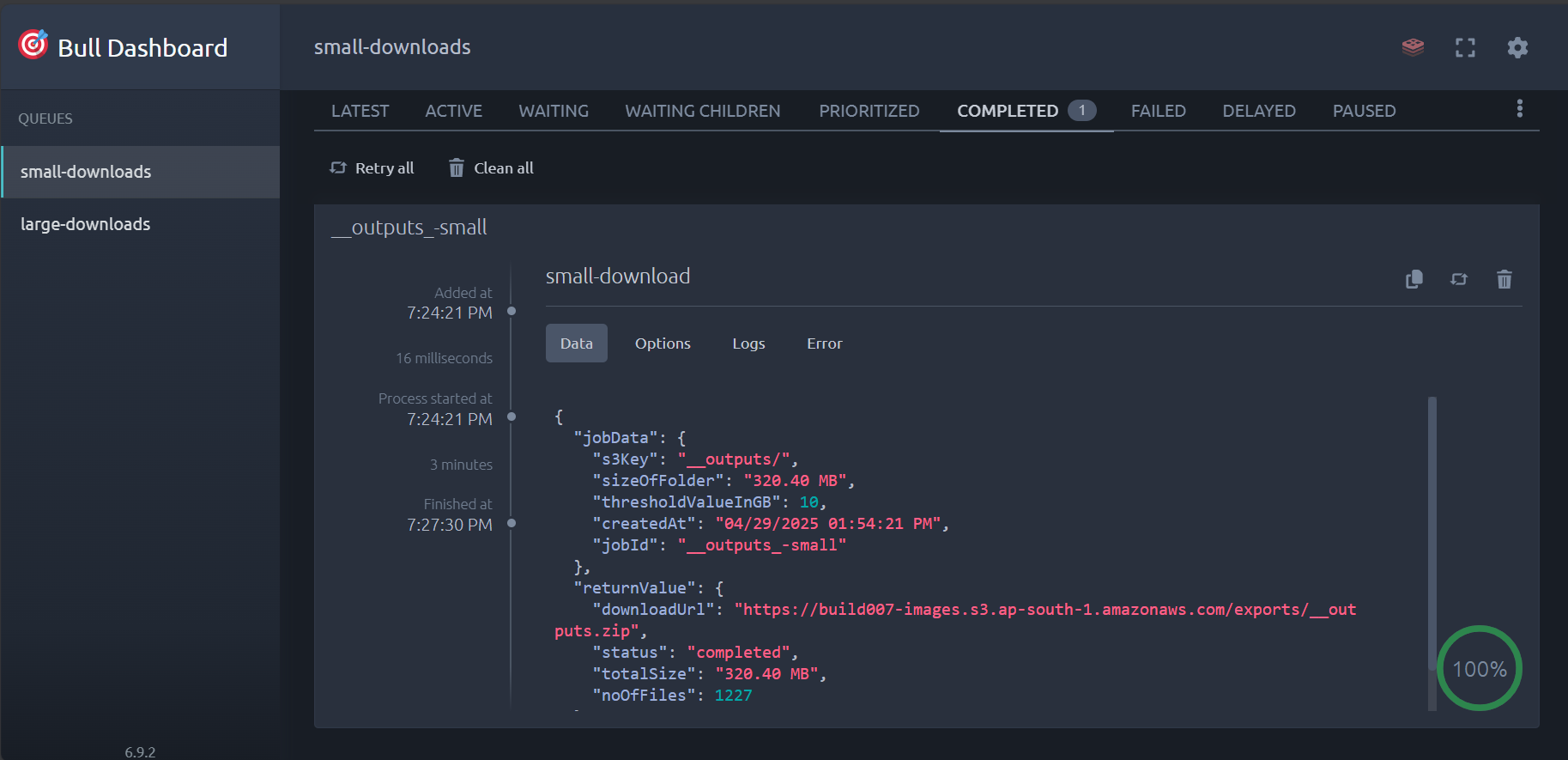
Dashboard Overview (BullMQ Dashboard)
API Reference
Integrate StreamVault into your applications with our simple API.
Request Body:
{
"s3Key": "path/to/s3/folder"
}Response:
{
"message": "Small download job created successfully",
"s3Key": "__outputs/",
"sizeOfFolder": "320.40 MB",
"thresholdValueInGB": 10,
"createdAt": "04/29/2025 01:54:21 PM",
"jobId": "__outputs_-small",
"isLargeDownload": false
}Response:
{
"message": "Job details retrieved successfully",
"jobDetails": {
"jobId": "job_14a72b9e3d",
"name": "large-download",
"data": {
"s3Key": "path/to/s3/folder",
"sizeOfFolder": 16492674825,
"progress": 78,
"state": "active"
}
}
}{
"downloadUrl": "https://bucket-name.s3.bucket-region.amazonaws.com/path-of-archive",
"status": "completed",
"totalSize": "320.40 MB",
"noOfFiles": 1227
}Ready to Transform Your S3 Download Experience?
Join the StreamVault community today and overcome the limitations of AWS S3's native interface.
By contributing, you agree to our ISC License